Прошло чуть больше полутора лет, с тех пор как искусственный интеллект (ИИ) стремительно ворвался в нашу жизнь. Конечно, понятие ИИ возникло намного раньше: в 1956 г. этот термин предложил американский информатик Джон Маккарти, а по прошествии некоторого времени так стали называть научное направление по моделированию видов человеческой деятельности, которые считаются интеллектуальными. Много сделали для популяризации ИИ фантастическая литература и кинематограф.
Собственно, до 2022 г. обычный человек воспринимал ИИ или как фантастику, или как занятие для узкого круга специалистов. Появление в ноябре 2022 г. генеративных сервисов, доступных массовому пользователю (ChatGPT), и последовавший за этим бум генеративных сервисов, сделало инструменты ИИ обыденностью.

Авторы Юрий ЧЕХОВИЧ, исполнительный директор компании Антиплагиат; Андрей ГРАБОВОЙ, руководитель отдела исследований компании Антиплагиат; Герман ГРИЦАЙ, разработчик-исследователь компании Антиплагиат
Технологии ИИ существенно изменили нашу жизнь, и наверняка изменения продолжатся. Конечно, идея порабощения человечества искусственным разумом пока ещё не выглядит реалистичной. Даже до создания так называемого сильного ИИ, способного мыслить и осознавать себя как отдельную личность, пока далековато¹
¹ См., например, Бруссард Мередит. Искусственный интеллект: Пределы возможного. М.: Альпина Диджитал, 2018. 362 с.
Тем не менее на наших глазах появились и развиваются технологии, возможности которых ещё несколько лет назад казались недостижимыми. Генеративные сервисы, основанные на больших языковых моделях (англ. Large Language Models, LLM), уже стали привычным для многих людей инструментом. Существенную роль в этом сыграли простота взаимодействия с сервисами и относительно высокое качество искусственных текстов: теперь они очень похожи на написанные людьми. Ещё одним важным свойством генеративных моделей, обеспечившим им высокую популярность, оказалась формальная оригинальность, т.е. отличие от всех текстов, существовавших до него. Естественно, речь чаще всего идёт не о смысловом различии, а скорее о буквальном. Тем не менее в эпоху повсеместного использования сервисов обнаружения заимствований [1–3] такое свойство обеспечило дополнительную привлекательность генерируемых текстов. Одной из сфер, которая подвергается серьёзному влиянию наблюдаемого технологического прорыва оказалась область науки и образования, весьма чувствительная к проблеме текстовых заимствований [4, 5]. Вероятно, на популярности генеративных сервисов сказался ореол таинственности и чудесности, сформировавшийся вокруг новых технологий. В силу того что генеративные алгоритмы обладают высокой сложностью, а их результаты выглядят недетерминированными, у массового пользователя возникает ощущение, что тексты создаются каким-то магическим способом. Заметное влияние на такие ощущения оказывает и сам термин «искусственный интеллект», которым пытаются объяснять сейчас едва ли не все современные результаты, получаемые в computer sciences. В статье мы постараемся дать полное разоблачение «магии генеративных сервисов». Расскажем об эволюции генеративных технологий в течение последних 40 лет, об особенностях и ограничениях современных моделей, понимание которых, по нашему мнению, поможет студентам, преподавателям, учёным избегать рисков, возникающих при использовании генеративных сервисов. Мы изложили материал в популярной форме, так чтобы можно было разобраться в принципах работы генеративных сервисов, обладая общей эрудицией и определёнными навыками работы с компьютером. При этом ключевые понятия снабжены ссылками, которые позволят читателям в случае необходимости углубиться в область самостоятельно.
А теперь, чтобы разобраться в устройстве языковых моделей, нам необходимо отступить на пару шагов назад и вспомнить…
…ЧТО ТАКОЕ ТЕКСТ?
А точнее, как текст представлен в памяти компьютера. Текст для человека — это последовательность символов какого-то алфавита, включая буквы и различные разделительные символы. В памяти компьютера каждому символу соответствует свой номер, и текст представлен последовательностью номеров соответствующих символов. Текст как последовательность символов удобно хранить, но неудобно использовать при решении интеллектуальных задач. Поэтому «с точки зрения» генеративных сервисов и моделей ИИ текст — это последовательность токенов. Токеном в обработке естественных языков называют подпоследовательность символов из текста, несущую определённую смысловую нагрузку.
Существует множество подходов к разбиению текста на токены. Например, некоторые из них учитывают структуру слова либо частотные характеристики совместной встречаемости символов в словах. Когда текст разбивается на последовательность токенов из словаря, каждому из них ставится в соответствие номер в словаре, а текст оказывается просто последовательностью номеров токенов. На рис. 1 показано разбиение фразы «Мама мыла раму» на токены для двух различных словарей.

Естественным и важным ограничением всех методов, работающих с текстом как с последовательностью токенов, является ограниченность списка токенов. То есть если в тексте встретится неизвестный токен, метод воспримет его примерно так же, как человек, который обнаружит в тексте незнакомый символ из другого алфавита, скажем какой-то иероглиф: слово будет восприниматься как неизвестный токен. Такое ограничение словаря автоматически переносятся и на работающую с этим словарём модель. Если в текстах встречается много неизвестных токенов, то качество работы всех методов существенно снижается.
Для решения этой проблемы специалисты оценивают полноту используемого словаря токенов, например как долю покрытия словарными токенами реальных текстов. Популярным методом сейчас является BPE/Unigram-токенизация, которая строит словарь токенов, имеющий хорошую полноту покрытия текстов, хотя и не стопроцентную [6–8].
В этой статье мы будем считать, что токены в тексте — это слова и знаки препинания. Разобравшись с тем, как текст разбивается на токены, давайте вернёмся к генерации осмысленного текста и попробуем понять…
…ЧТО ТАКОЕ ЯЗЫКОВАЯ МОДЕЛЬ?
«Под капотом» у каждого современного генеративного сервиса находится языковая модель — алгоритм, который решает довольно простую задачу: зная начальную часть фразы (несколько последовательных токенов), он выдаёт для каждого токена из словаря вероятность оказаться следующим в этой фразе. Это очень похоже на работу функции T9 в мобильном телефоне, которая предлагает варианты продолжения написанного текста. Результаты работы модели зависят от качества расчётов вероятностей, а также от способа определения того, каким же токеном будет продолжен текст, когда вероятности уже установлены.
В первую очередь в голову приходит так называемый жадный метод, когда на каждом шаге выбирается токен, имеющий максимальную вероятность (рис. 2а). При всей простоте такого метода он имеет существенный недостаток — плохую вариативность генерации: для одинаковых запросов (начала фразы) метод выдаёт один и тот же результат.
Более сложным является метод Beam-search, в котором на каждом этапе генерируется несколько вариантов токенов (рис 2б). В результате получается несколько вариантов текста, и среди них выбирается лучший по некоторому критерию. Данный подход более вариативен, чем «жадный», но не позволяет создавать по-настоящему «человеческие» тексты.
Наиболее популярным способом генерации является семейство методов сэмплирования токенов. При сэмплировании токены из словаря выбираются случайным образом, но не равновероятно, а с вероятностью, которую указала языковая модель (рис. 2в). Метод обладает достаточной вариативностью, а его недостатки связаны с возможностью продолжить текст токенами, имеющими низкую, но не нулевую вероятность. В результате в тексте возникают конструкции вида «стремительный домкрат». Для улучшения качества результата можно, например, удалять токены с самой низкой вероятностью и выбирать продолжение из наиболее вероятных.
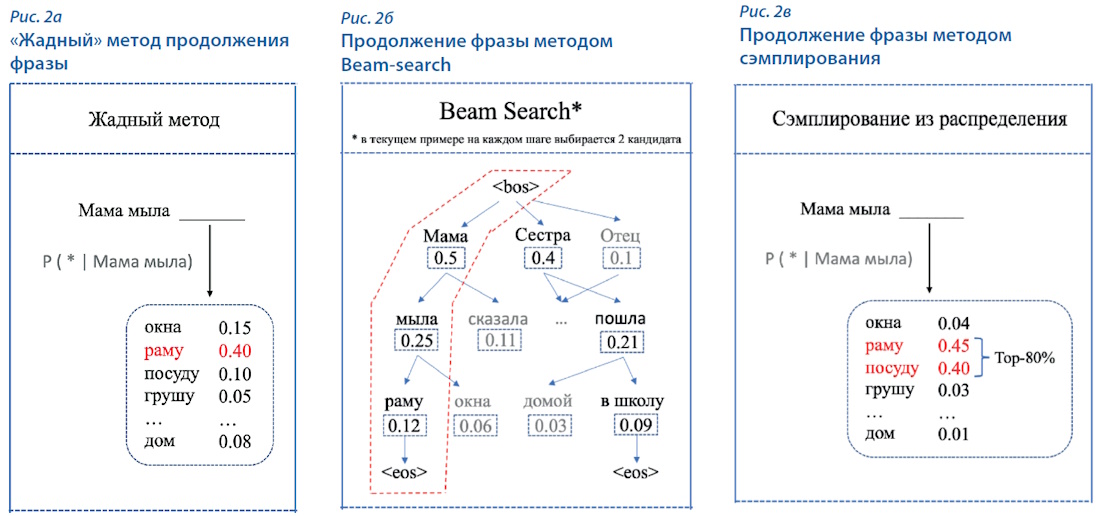
В каждом из приведённых примеров мы показывали продолжение новым токеном конкретной фразы. Очевидно, что, для того чтобы языковая модель позволяла генерировать максимально «человеческий» текст…
…РАЗМЕР КОНТЕКСТА ОЧЕНЬ ВАЖЕН!
Огромное влияние на качество генерации оказывают размер и способ учёта контекста — той самой части фразы, на основе которой модель рассчитывает вероятность токенов быть продолжением текста. В процессе развития языковых моделей развернулась настоящая гонка за увеличение размера контекста, а также за адекватность его учёта при расчёте вероятностей.
Одной из самых простых является n-граммная языковая модель. В этой модели для всех возможных вариантов n первых токенов текста и каждого возможного следующего токена указано значение вероятности того, что этот токен продолжит текст. Все возможные n токенов формируются из обучающего корпуса текстов. Если какие-то n не встретились в корпусе ни разу, модель не сможет их продолжить. Вероятности для токенов продолжить существующие n — это частоты встречаемости конкретного токена после данных n токенов в заданном корпусе. Чаще всего n-граммные модели используют длину контекста в два-три токена (рис. 3).
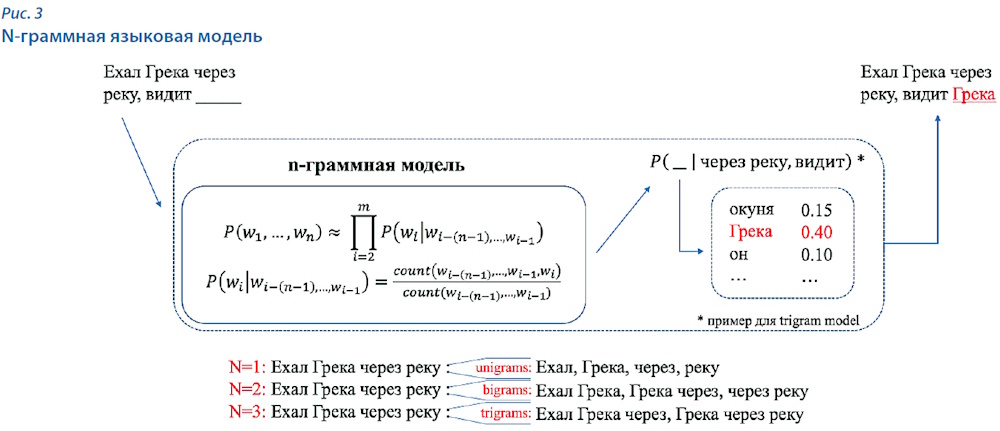
Данный метод отлично подходит для базового решения, но имеет существенный недостаток: у него отсутствует обобщающая способность. То есть модель не имеет возможности работать с новыми n-граммами, которые отсутствовали в обучающих текстах.
Серьёзным шагом в улучшении качества моделей генерации текстов стали предложенные в 1994 г. рекуррентные нейросетевые модели (Recurrent Neural Network, RNN) [9], в частности их доработка в виде архитектуры модели sequence-to-sequence (seq2seq). Эта модель предсказывает вероятность каждого следующего токена на основе всей последовательности, которая была подана на вход модели, а также ранее сгенерированных токенов (рис. 4). Архитектура seq2seq показала неплохие результаты в задаче перевода и перефразирования текстов на уровне предложений. Основной проблемой данной модели стала слишком короткая «память» модели генерации последовательности. Это приводило к тому, что для генерации токена в основном использовалась информация только от ближайших токенов.
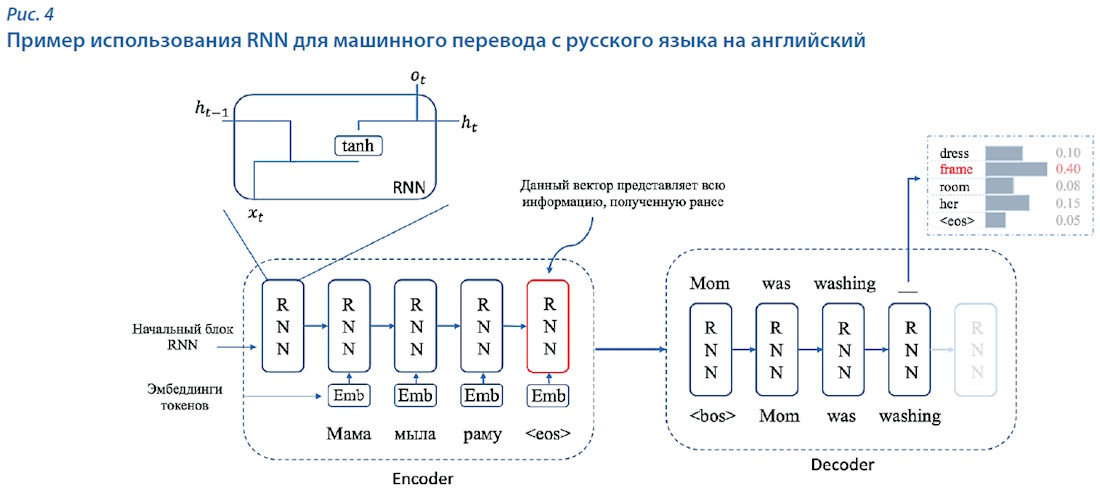
Для решения проблемы с короткой «памятью» Hochreiter и Schmidhuber в 1997 г. предложили модель Long Short-Term Memory (LSTM) [10], которая позволяла хранить информацию о дальних токенах и учитывать их вклад при генерации вектора вероятностей (рис. 5). В этой модели размер учитываемого контекста в среднем составлял десятки токенов. LSTM показала себя достаточно хорошо, превзойдя результаты RNN. Но и у неё был недостаток: для каждого генерируемого токена все слова из длинного контекста являлись одинаково важными, при этом порядок слов в контексте не учитывался.
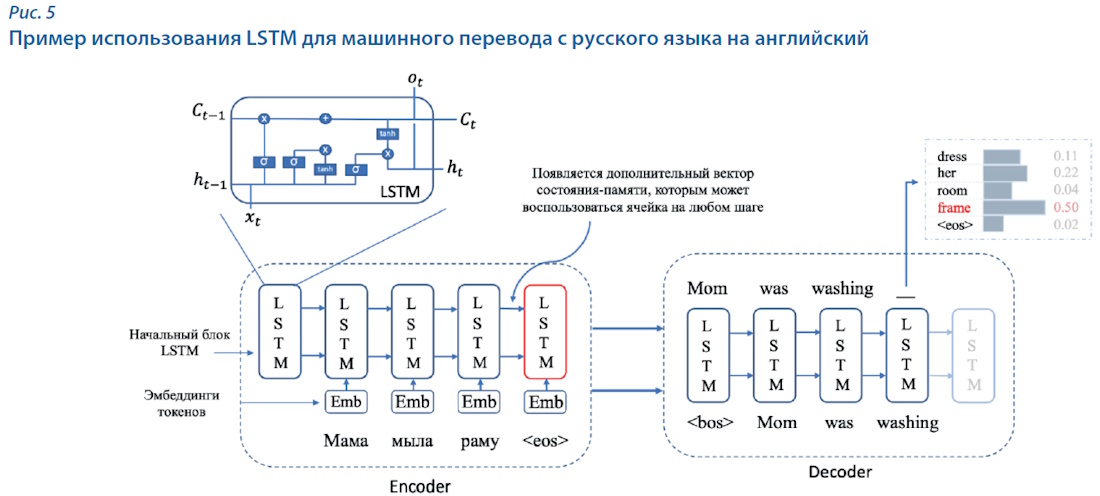
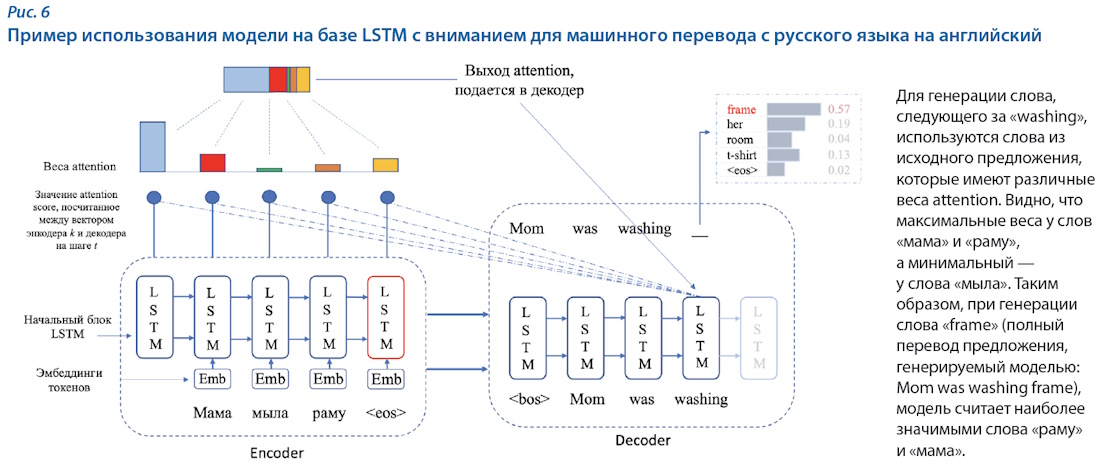
Только через 20 лет, в 2017-м, с целью решения проблемы выделения важных фрагментов текста для генерации токенов был предложен механизм внимания (Attention) [11]. Сначала он применялся в уже известных моделях LSTM и RNN с целью выбора наиболее релевантных токенов в исходной последовательности для генерации следующего токена (рис. 6). Механизм внимания показал высокие результаты, вследствие чего была предложена новая архитектура нейросетевых моделей, которую назвали Transformer. Новая модель показала высокое качество решения задачи машинного перевода и до сих пор является основополагающей во всех современных языковых моделях. Важным ограничением архитектуры Transformer является максимальная длина фрагментов, с которыми работает модель. Обычно она находится в пределах 512–2048 токенов.
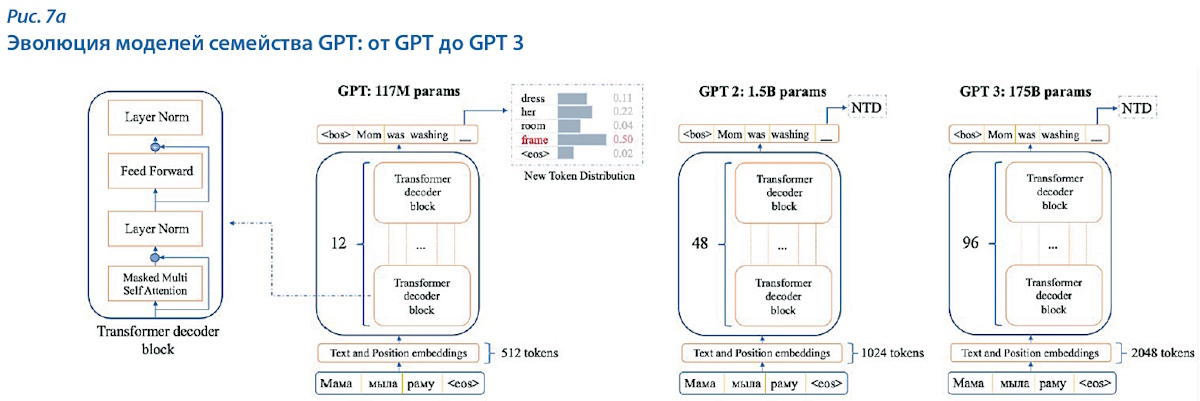
Популярность Transformer привела к появлению новых языковых моделей на основе этой архитектуры. Одними из самых популярных моделей являются представители семейства генеративных предобученных трансформеров (Generative pre-trained transformer, GPT), представленные в 2018 г. компанией OpenAI [12]. Первая модель GPT была обучена всего на 7 тыс. книг и включала 117 млн параметров (переменных, значения которых устанавливаются при обучении и используются при последующей работе модели). Максимальный размер текста, который обрабатывала модель, составлял всего 512 токенов [13]. Данную модель можно считать достаточно скромной по результатам из-за малого объёма обучающего корпуса.
Модель GPT 2, представленная в 2019 г., содержала 1,5 млрд параметров. Принципиально архитектура модели при этом не изменилась. GPT 2 была обучена не только на книгах, как её предшественница, но и на текстах большого количества интернет-сайтов. В GPT 2 появилась возможность генерировать большие связные тексты, что обеспечило ей значительный успех. Модель поддерживает генерацию текстов до 1024 токенов и учитывает все токены, заданные ей в качестве исходных данных [14].
Дальнейшее увеличение числа параметров до 175 млрд привело к появлению в 2020 г. модели GPT 3 [15]. Основной особенностью стало то, что она была обучена на более чем 500 Гб текстов, собранных из Интернета и включавших художественную литературу, новостные сайты и даже исходники программного кода. В рамках этой модели впервые появилась возможность генерировать программный код для решения несложных задач. Контекст генерации токенов был увеличен до 2048 (рис. 7а).
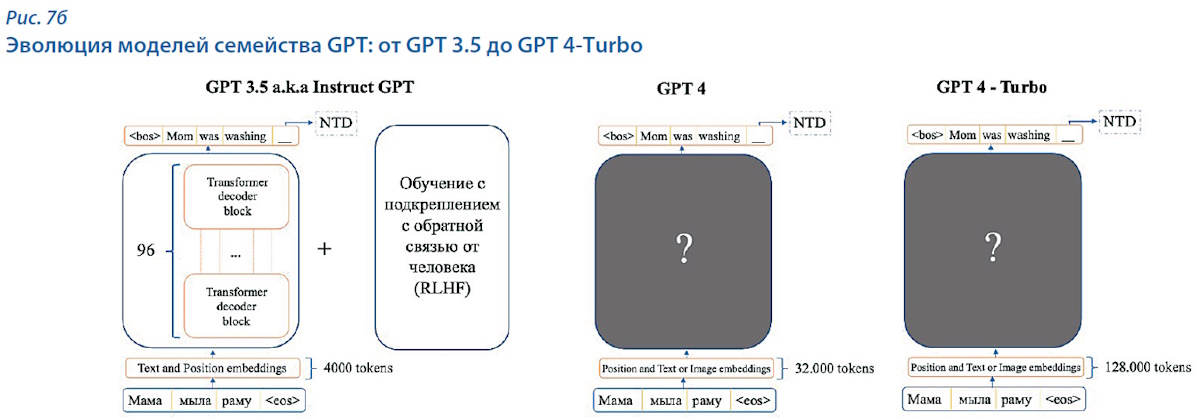
После того как обучение нейросети на огромном массиве контента привело к появлению GPT 3, добавление новых сырых данных, скорее всего, не привело бы к увеличению качества генерации. Для того чтобы получить следующий значимый прирост качества, разработчики использовали обратную связь с пользователями на основе технологии обучения с подкреплением [16]. Таким образом появилась GPT 3.5, которая архитектурой модели не отличается от GPT 3, но позволяет при генерации использовать контекст до 4 тыс. токенов.
Одной из основных проблем ранее описанных моделей GPT является то, что они работают только с текстами. GPT 4 позволяет работать не только с текстовым слоем, но и с любыми объектами в документах, в том числе с изображениями. К сожалению, авторы не предоставляют конкретных архитектурных решений, использованных для разработки [17]. Очевидно, что для обработки изображений используются модели, основанные на других принципах, поэтому оставим этот вопрос за рамками данной статьи. Известно, что модель поддерживает контекст до 32 тыс. токенов, что позволяет ей работать с довольно большими текстами. Это ещё сильнее повышает привлекательность сервиса для использования при работе с научными и учебными документами.
Современная модель генерации GPT 4 — Turbo, представленная в середине ноября 2023 г., позволяет использовать до 128 тыс. токенов при генерации текста. Подробные технические характеристики, к сожалению, пока не обнародованы.
В целом GPT версии 3.5 и выше являются в большей степени коммерческим продуктом, чем научным. Помимо собственно языковой модели сервис использует многочисленные программы для постобработки результатов. Вероятности токенов в современных решениях GPT конечному пользователю уже недоступны.
В настоящее время существуют другие разработки, которые находятся в открытом доступе и могут быть использованы как языковые модели. Примерами таких моделей являются LLaMA [18], Alpaca [19], LLaMA2 [20], Mistral [21].
Последние несколько лет развития абсолютно всех языковых генеративных моделей показывают, что…
…КЛЮЧ К ПОВЫШЕНИЮ КАЧЕСТВА ГЕНЕРАЦИИ — ХОРОШИЕ ДАННЫЕ!
После появления модели GPT 3 стало понятно, что тексты, доступные на открытых интернет-сайтах, не позволяют повышать качество работы моделей. Новый импульс к росту качества дали технологии дообучения моделей с помощью результатов вопросно-ответных систем взаимодействия с пользователями — чатов. Пользователи, общаясь с сервисом в чате, дают обратную связь, которую компания использует для улучшения моделей. Использование таких данных позволило значительно повысить качество генерируемых текстов. При этом для заметного улучшения потребовалось совсем немного таких данных по сравнению с объёмами данных первоначального обучения. В 2023 г. стало очевидно, что подготовка данных — это один из важнейших факторов для получения высококачественных моделей.
Использование небольшого объёма контента для дополнительного обучения моделей имеет и отрицательные стороны. Во-первых, если данные являются узконаправленными, то и тексты, сгенерированные моделью, также будут иметь значительный перекос в области, представленные в обучающих данных. С другой стороны, полученный перекос может иметь и положительные эффекты, если нужен инструмент, моделирующий определённый бизнес-процесс: примером такого сервиса может служить модель для генерации кулинарных рецептов или же ещё более узкий сервис — генерации рецептов хлебобулочных изделий. Во-вторых, использование узконаправленных данных возможно и для генерации различных манипуляций в сгенерированных текстах с целью получения какой-либо выгоды. В последние годы очень распространённой является задача детекции фейковых новостей, теперь же, с развитием генеративного ИИ, эта задача стала ещё более актуальной [21].
Стоит отметить, что использование обратной связи от пользователей для дообучения моделей также имеет и недостатки. С одной стороны, количество высококачественных данных растёт, с другой — появляется всё больше сгенерированного контента и его среднее качество значительно падает. Повышается вероятность того, что обучение новых моделей будет производиться на всё более значительной доле сгенерированного текста. Мы предполагаем, что это приведёт к росту потребности в сервисах валидации и оценки данных.
Впрочем, это пока ещё возможное будущее, а вот…
…С ЧЕМ СВЯЗАНЫ РИСКИ ПОЛЬЗОВАТЕЛЕЙ СЕЙЧАС?
Как мы показали выше, современные генеративные сервисы создают наиболее вероятные текстовые последовательности с помощью алгоритмов, обученных на большом корпусе текстов и наборе ответов пользователей. Сгенерированные таким образом последовательности выглядят правдоподобными, с точки зрения человека, но выбор продолжения текста с помощью сэмплирования часто приводит к тому, что полученные последовательности содержат ложную информацию.
В литературе для этого явления используется термин «галлюцинация генеративных моделей». В последнее время появляется всё больше и больше способов оценки различных методов генерации по тому, как часто модели генерируют информацию, не соответствуют действительности, т.е. галлюцинируют.
Основные типы галлюцинаций генеративных моделей:
Одним из ключевых примеров является автоматическое реферирование (суммаризация) текстов, которая соответствует первому типу галлюцинаций. При суммаризации предполагается, что результатом работы языковой модели является краткое содержание исходного текста, которое ему точно соответствует. Часто при генерации реферата или аннотации языковая модель производит подмену понятий из исходного текста либо «додумывает» информацию, которой нет в исходном тексте, что может привести к неверному понимаю пользователем оригинального контента.
Другим примером является получение ответов от модели на узкотематические вопросы. Часто такие ответы могут содержать не совсем корректную либо вовсе ложную информацию. Рассмотрим примеры, которые могут быть проверены любым пользователем в открытых источниках. Так, на запрос «О чём книга "Муму?"» модель ChatGPT в начале 2023 г. выдавала некорректный ответ:
«“Муму” — это роман писателя Ивана Тургенева, опубликованный в 1954 году. Книга рассказывает историю простой девушки Герасима, которая была куплена богатой дворянкой и превращена в служанку. Главной душой и опорой Герасима в жизни становится его любимая корова Муму».
Ещё один пример — запрос «Сколько стран в мире начинаются на букву В?», в рамках которого модель YandexGPT в конце 2023 г. выдала также некорректный ответ: одна страна была учтена два раза, присутствуют также другие ошибки.
«В мире 7 стран, названия которых начинаются на букву В:
Отдельно заметим, что повторы при генерации текста — достаточно частое явление у языковых моделей, и это нередко используется в качестве признаков при детекции искусственных текстов.
Мы привели эти примеры только как иллюстрации. Заметно, что целенаправленные усилия разработчиков уменьшают число таких ложных ответов, но они всё ещё присутствуют в результатах всех современных моделей. Важно, что архитектура современных генеративных сервисов не делает галлюцинации моделей невозможными или даже маловероятными.
В целом высокие риски использования результатов работы генеративных сервисов связаны с завышенной оценкой их возможностей и соответственно с недооценкой роли пользователя в анализе готового текста. Активное использование термина «искусственный интеллект» создаёт впечатление, что текст создаётся не компьютерной программой, а компетентным и добросовестным экспертом. При этом, как мы показали ранее в статье, работает вероятностный алгоритм, пусть и обученный на огромном количестве текстов и дообученный на данных пользователей, но принципиально не способный критически оценивать качество и достоверность полученного результата.
Разработчики моделей предполагают, что достоверность и другие параметры качества результатов должны оценивать пользователи. А вот пользователи, зачастую не понимая, как работают генеративные сервисы, не занимаются такой оценкой или просто надеются на авось.
…А ВДРУГ «ПРОКАТИТ»?
Довольно часто студенты и авторы научных работ используют генеративные сервисы, несмотря даже на осознаваемые риски использования в работе текста низкого качества. На наш взгляд, это связано со сложившимся «рубежным» отношением ко многим типам работ: к курсовым, дипломам и даже к статьям и диссертациям. Нередко авторы исходят из предположения, что их работу никто не будет изучать серьёзно. И действительно, сложившиеся во многих учебных и научных организациях практики пренебрежения основами научной и академической этики, нормами авторского права демонстрируют, что указанные предположения обоснованны.
В условиях, когда, во-первых, значительная роль в образовательном и научном процессах отводится использованию автоматических средств контроля оригинальности (и других параметров качества) работы, а во-вторых, не менее существенные усилия студенты и авторы тратят на обеспечение соответствия формальным критериям качества, рассчитываемым этими средствами, очевидно, что использование средств искусственной генерации текста при подготовке письменных работ окажется повседневной практикой. Преподаватели и редакторы встретятся с необходимостью выявлять в работах искусственные фрагменты.
Около года назад в системе Антиплагиат — фактическом стандарте систем для обнаружения заимствований в России и странах СНГ — появилась функция, которая автоматически проверяет текст всех загружаемых работ и подсвечивает в них фрагменты текста, похожие на сгенерированные [23].
Использование функции в течение прошедшего года, экспертные оценки результатов её работы показывают высокие характеристики качества выявления искусственных текстов при низкой (менее 1% от всех срабатываний) доле ложноположительных случаев [24]. Появились средства детектирования искусственного текста и в других распространённых системах обнаружения заимствований. Таким образом, рассчитывать на то, что можно с помощью ИИ можно в работу быстро «налить воды» и это «прокатит», уже не приходится.
Тем не менее мы оцениваем генеративные сервисы, как очень полезный инструмент для использования студентами и учёными, которым, конечно, нужно научиться пользоваться корректно и этично. На наш взгляд, всех учёных, преподавателей, студентов должен волновать вопрос…
…КАК ВСЁ-ТАКИ ПРАВИЛЬНО ИСПОЛЬЗОВАТЬ ГЕНЕРАТИВНЫЕ СЕРВИСЫ?
Отметим, что процессы создания текста у естественного интеллекта и искусственного существенно различаются. Человек придумывает последовательность идей (образов, мыслей), раскрывая их в виде текста за счёт наполнения конкретными словами, держа при этом в уме цель (назначение) создаваемого произведения. На качество результата влияют как оригинальность идей, так и словарный запас автора. Генеративные модели действуют совершенно иначе — они дописывают слова по одному в конце текста, выбирая их из словаря в соответствии с вероятностями, заложенными при обучении модели. Они не продумывают идеи, а информацию о целях автора могут почерпнуть только из текста запроса (промпта). Незнание таких различий или недостаточное к ним внимание неизбежно создаёт проблемы у авторов, использующих генеративные сервисы.
Важно подчеркнуть, что в сложившихся условиях, когда технологии генеративных моделей продолжают стремительно развиваться, а практика и нормативная база использования искусственных текстов в научных и учебных работах пока не развита, было бы большой ошибкой вводить какие-либо нормативы на долю сгенерированного текста в работах. Это может породить нездоровые практики, от которых будут страдать добросовестные авторы, а неэтичные, наоборот, получат преимущества.
Генеративные сервисы быстро становятся инструментом столь же привычным и распространённым, как текстовые редакторы и интернет-поисковики, и нам кажется важным ввести в повсеместное использование правило обязательного декларирования авторами учебных и научных работ применённых ими средств ИИ с указанием целей и способов использования. Важно помнить, что ответственность за содержание работы всегда несут её авторы и не получится переложить её на ИИ.
ЛИТЕРАТУРА
Рубрика: Искусственный интеллект и нейросети
Год: 2024
Месяц: Июнь
Теги: ChatGPT Андрей Грабовой Нейросети Искусственный интеллект (ИИ) Юрий Чехович Герман Грицай